|
A deep learning researcher interested in computer vision and machine learning. Specifically my research interest lies in improving the quality of multi-modal representations and their interactions for various downstream applications to widen the capability boundaries, such as video understanding, video corpus moment retrieval, video scene boundary segmentation and visual grounding. Currently, I am a PhD student at the University of North Carolina at Chapel Hill, advised by Prof. Gedas Bertasius. Previously, I received Master's degree in Data Science at Seoul National University Visual Information Processing Lab, advised by Prof. Joonseok Lee. I also received Bachelor's degree in Computer Science, Engineering at University of Illinois at Urbana-Champaign. |

|
|
|
|
|
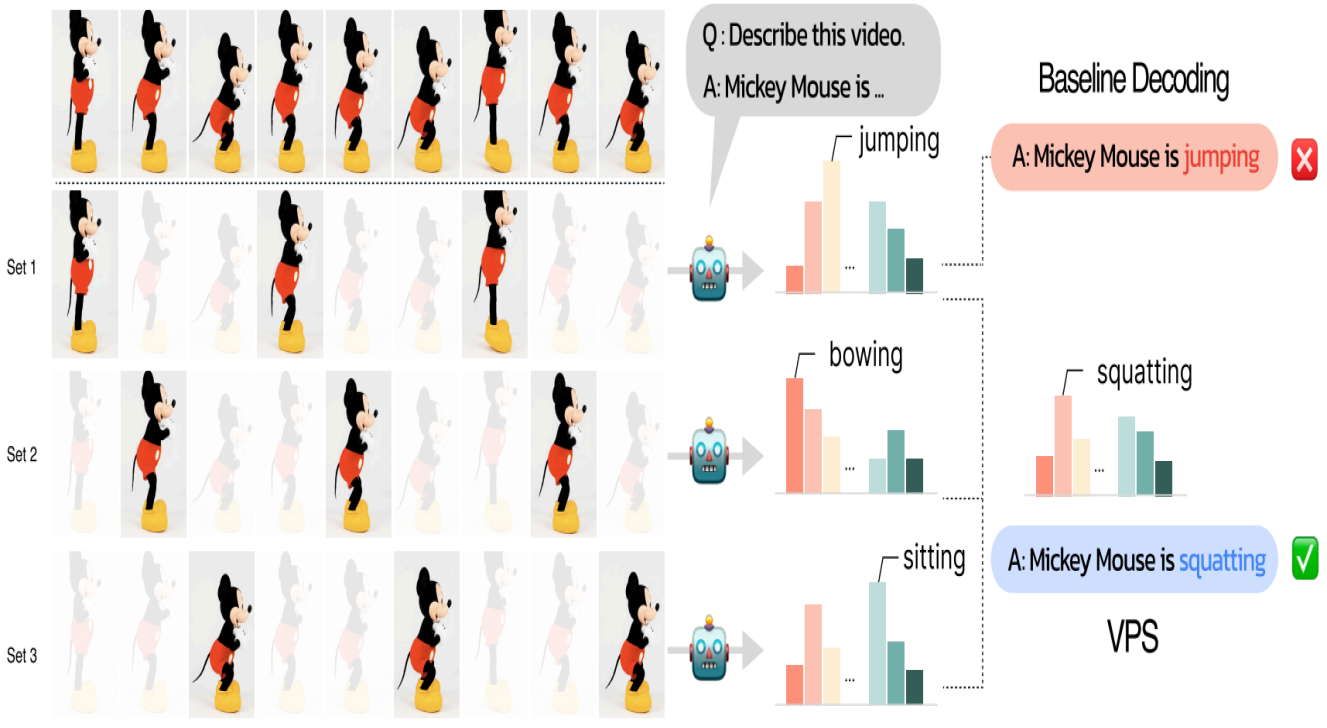

|
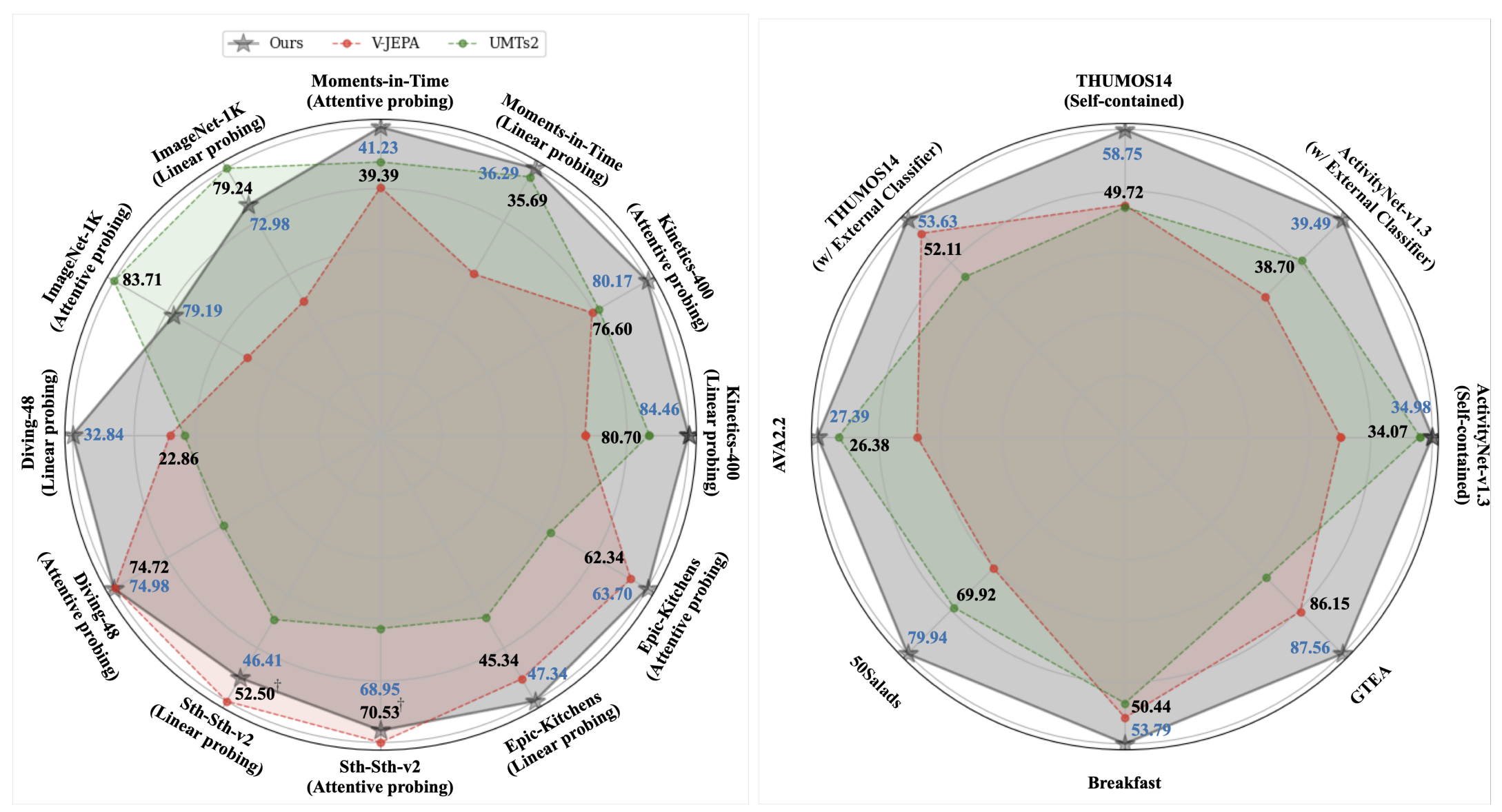
Hyungjin Chung*, Hyelin Nam, Jiyeon Kim, Hyojun Go, Byeongjun Park, Junho Kim, Joonseok Lee, Seongsu Ha, Byunghoon Kim arXiv, 2025 paper |
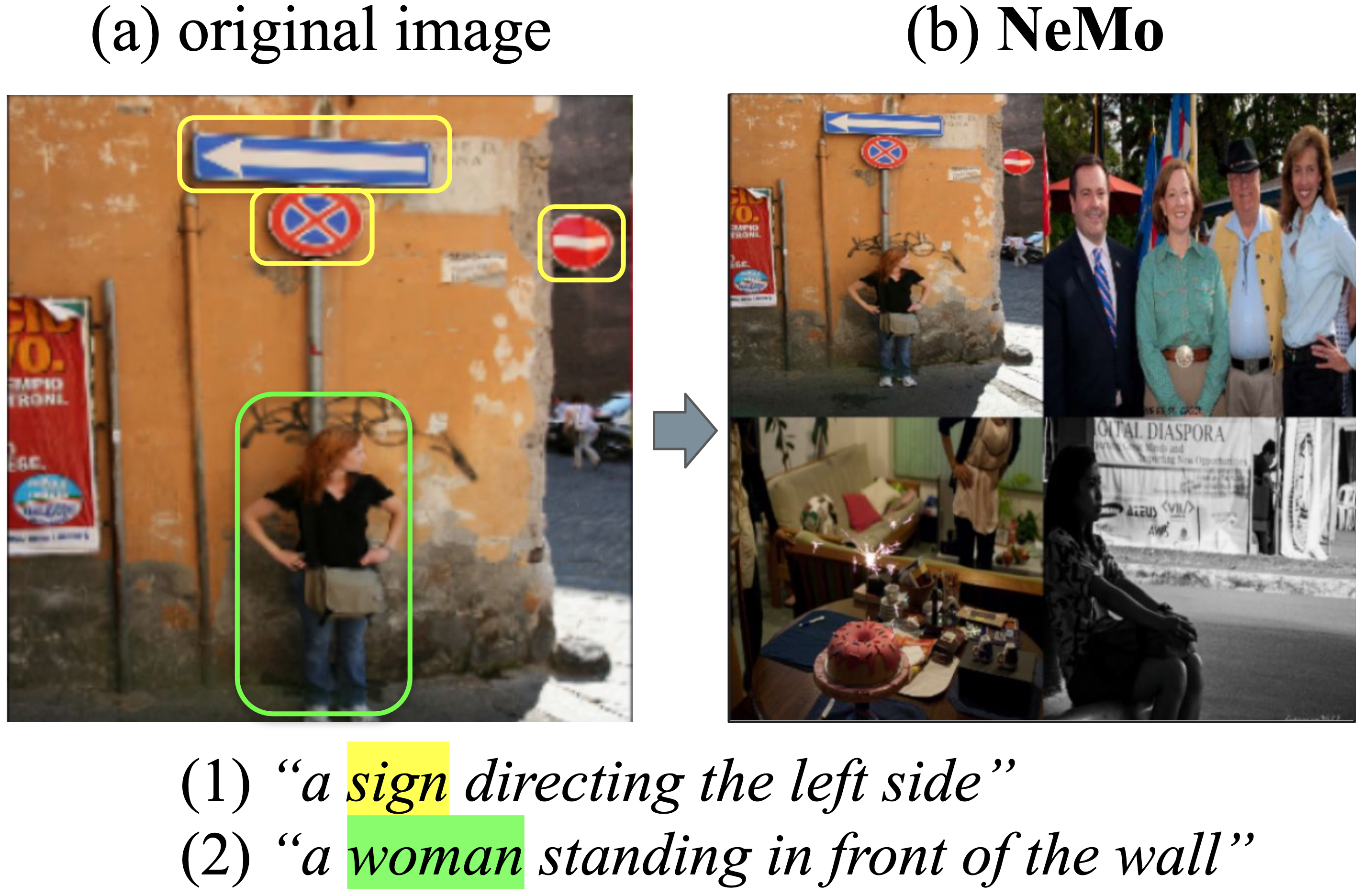
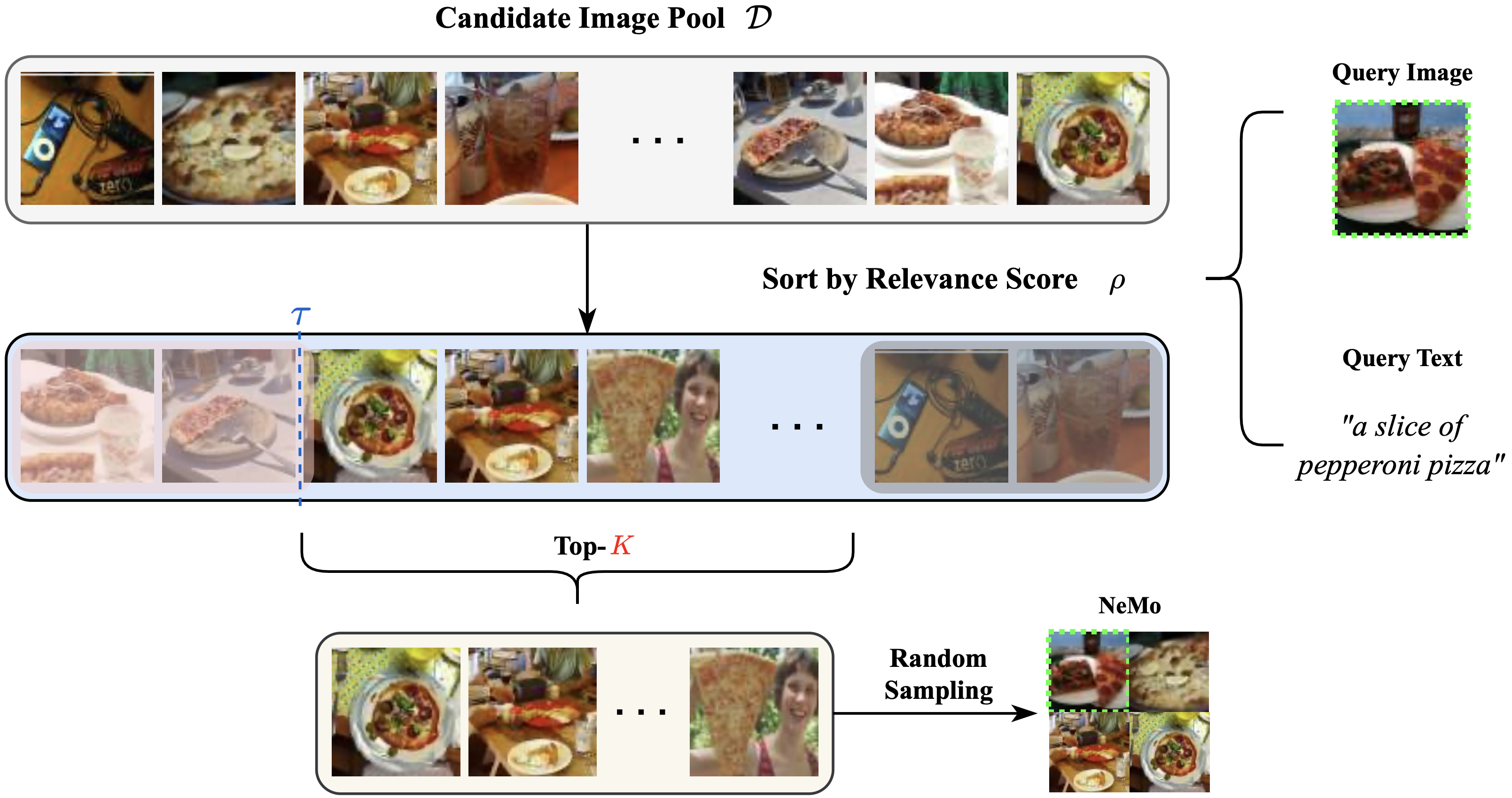
|
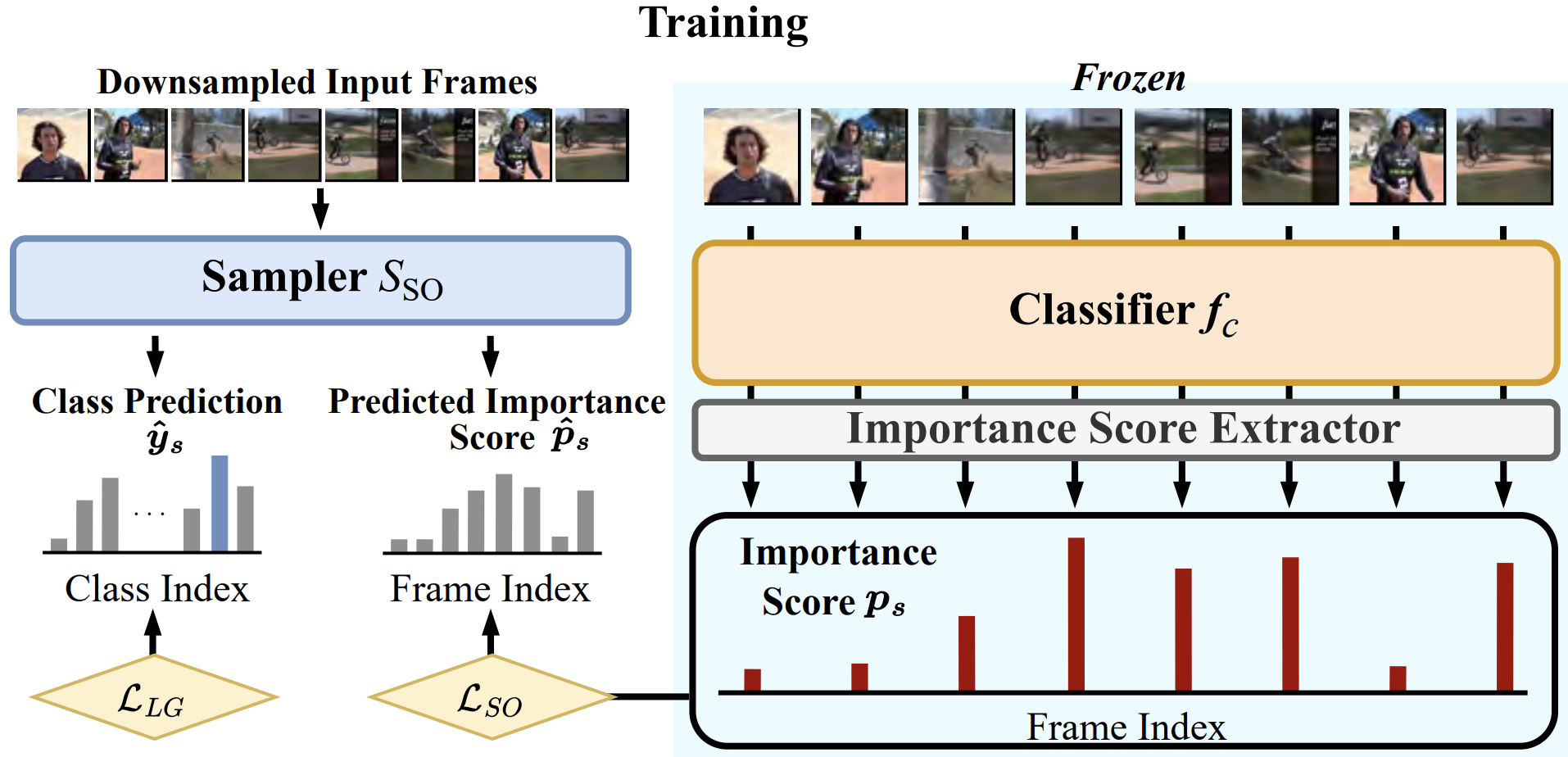
Seongsu Ha*, Chaeyun Kim*, Donghwa Kim*, Junho Lee, Sangho Lee, Joonseok Lee ECCV, 2024 paper |
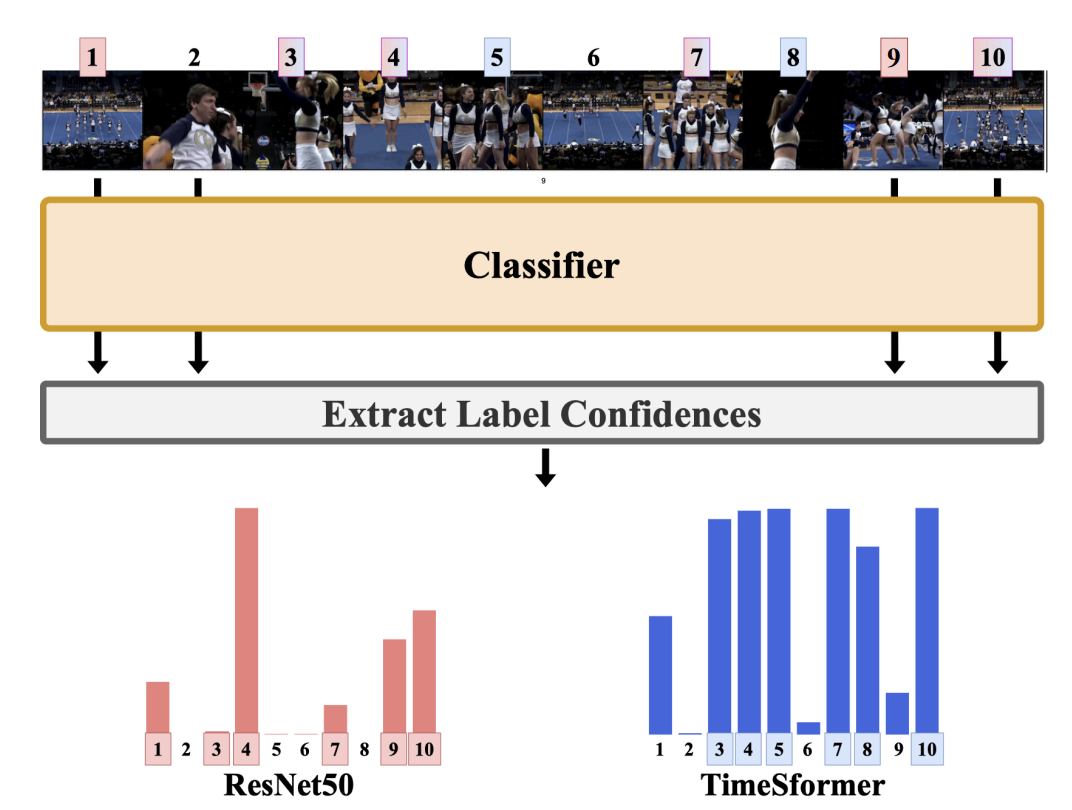
|
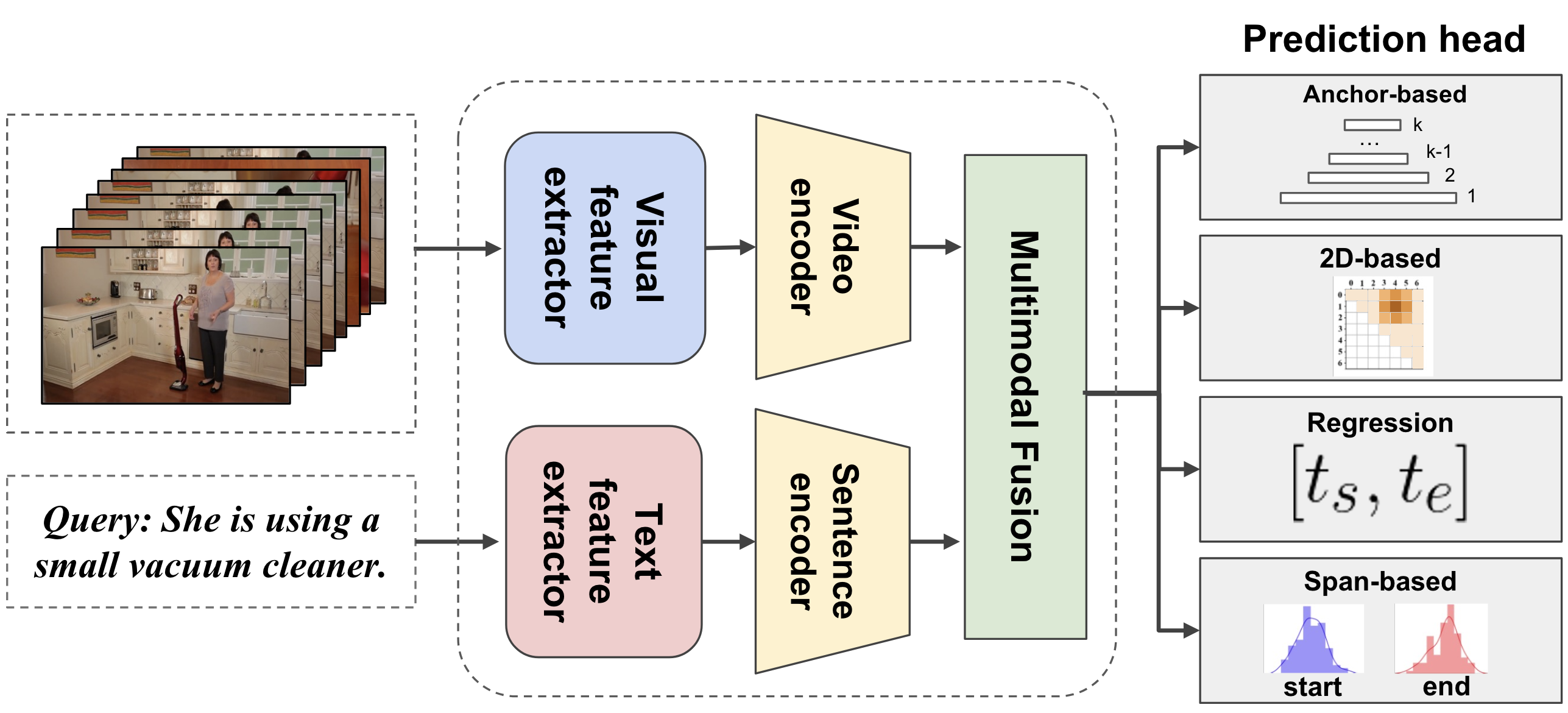
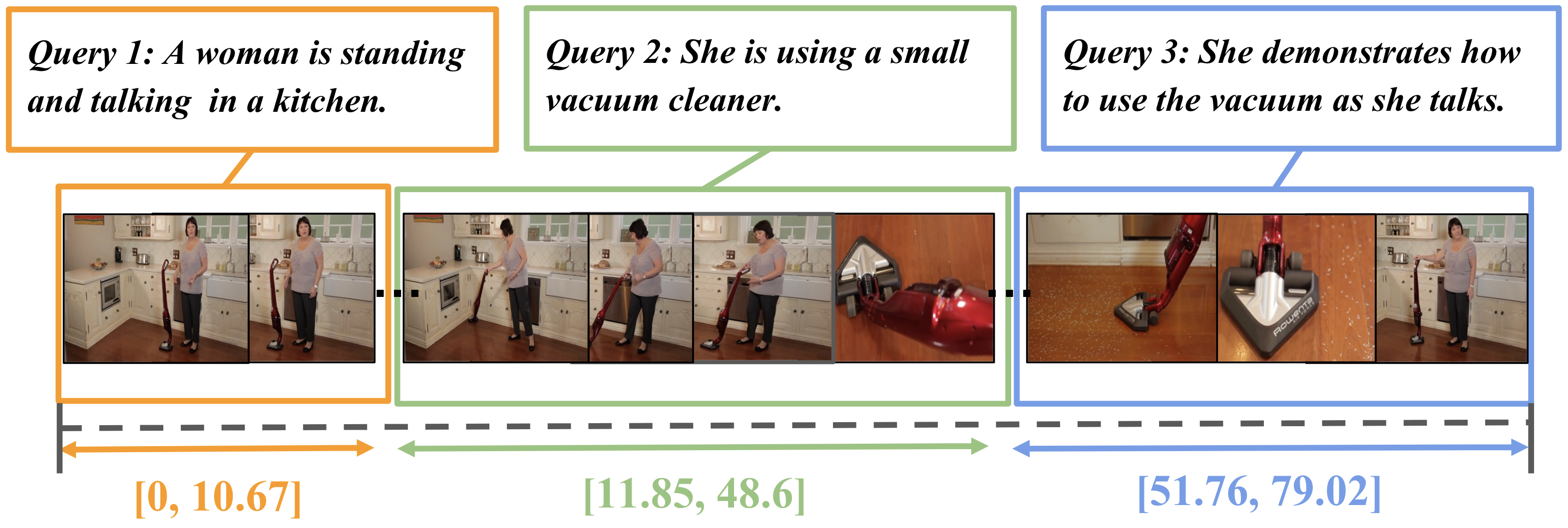
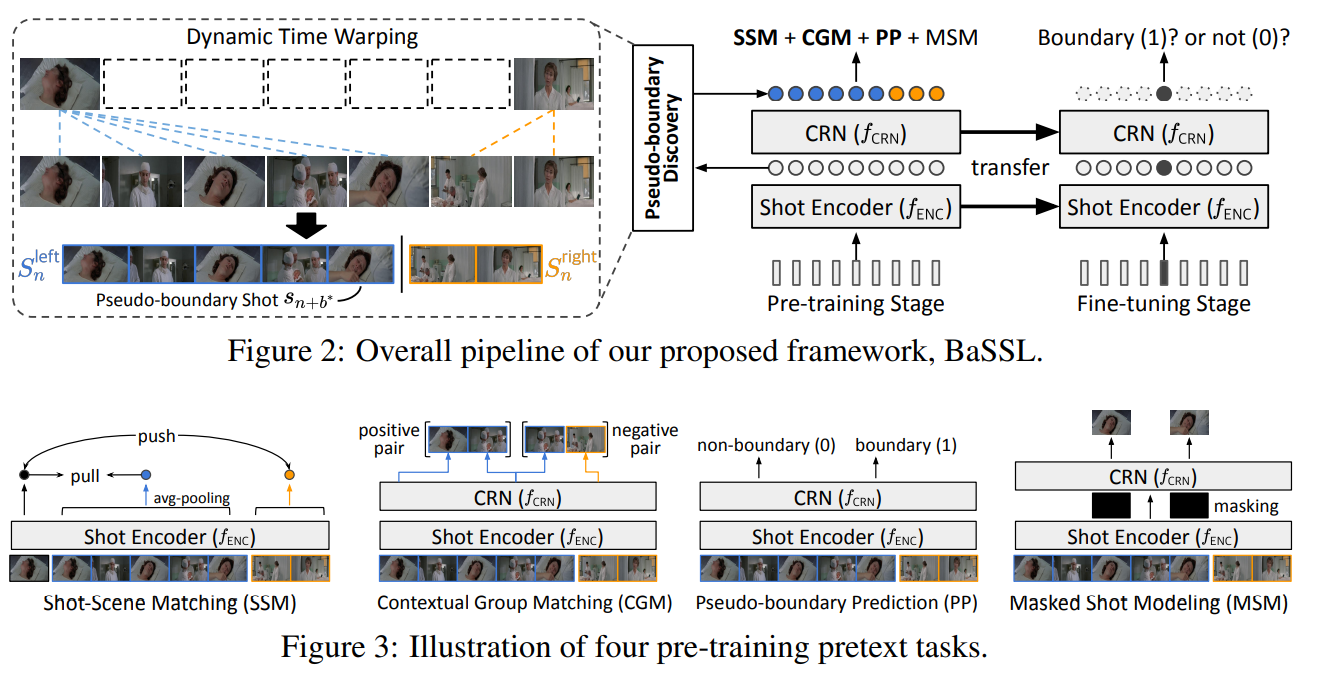
Junho Lee*, Jeongwoo Shin, Seung Woo Ko, Seongsu Ha, Joonseok Lee BMVC, 2024 paper |
|
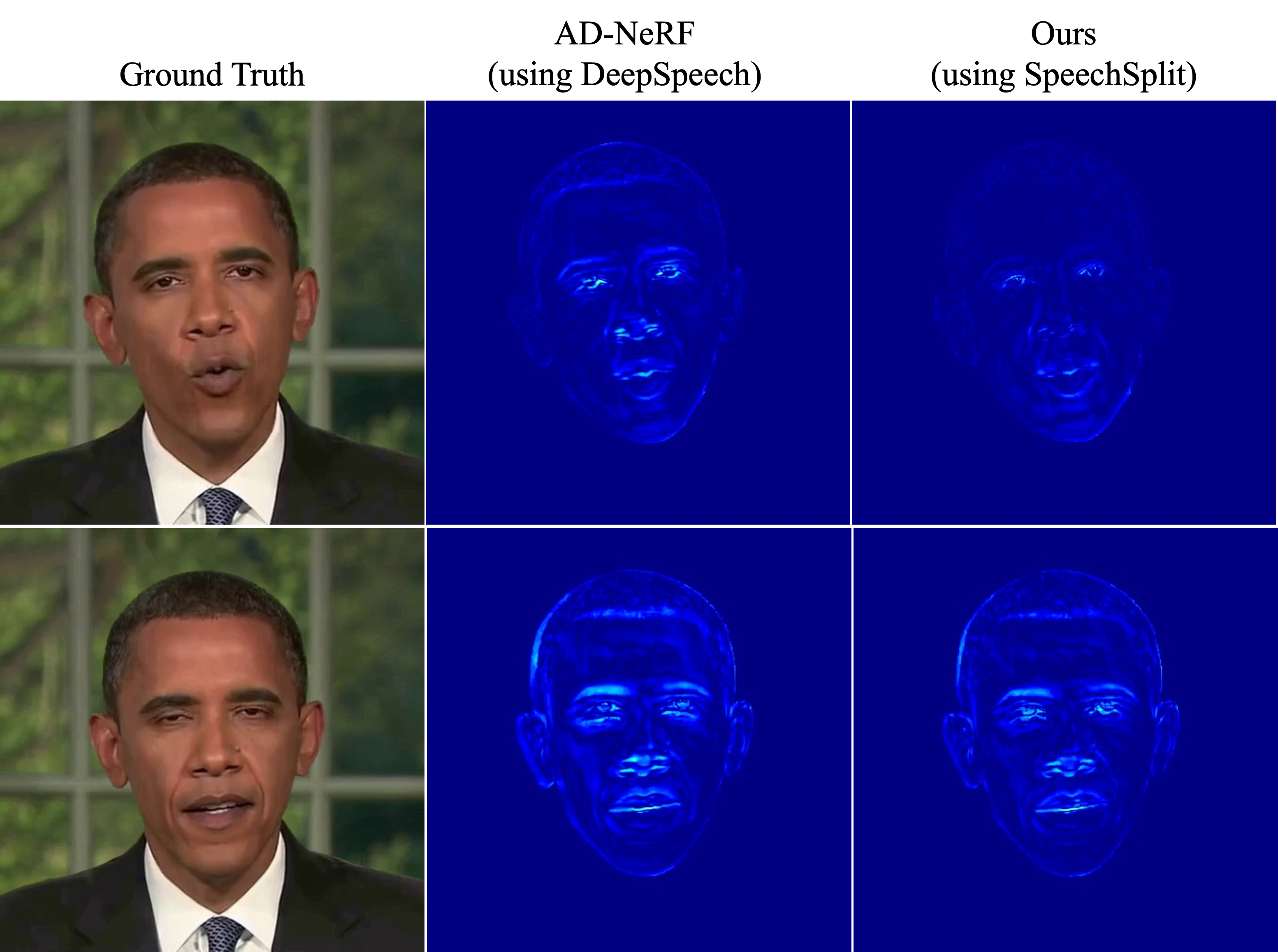
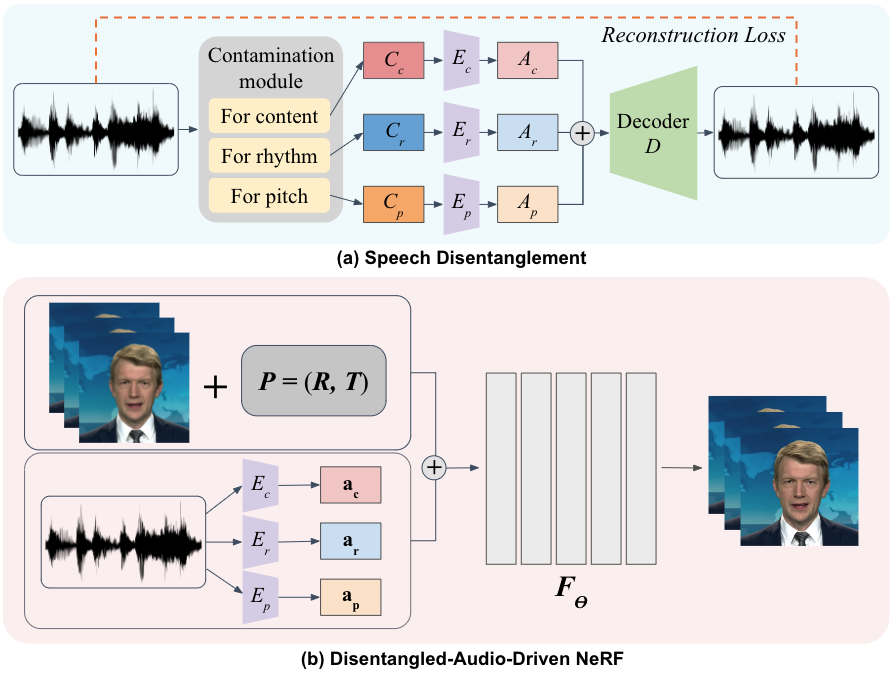
Jinyeong Chae*, Donghwa Kim*, Kwanseok Kim, Doyeon Lee, Sangho Lee, Seongsu Ha, Jonghwan Mun, Woo-Young Kang, Byungseok Roh, Joonseok Lee AISTATS, 2024 paper |
|
Seoyoung Lee*, Seongsu Ha*, Joonseok Lee CVPRW, 2023 paper |

|
Jonghwan Mun*, Minchul Shin*, Gunsoo Han, Sangho Lee, Seongsu Ha, Joonseok Lee, Eun-Sol Kim ACCV, 2022 paper |

|
Twelve Labs Technical Blog, 24.12 blog |
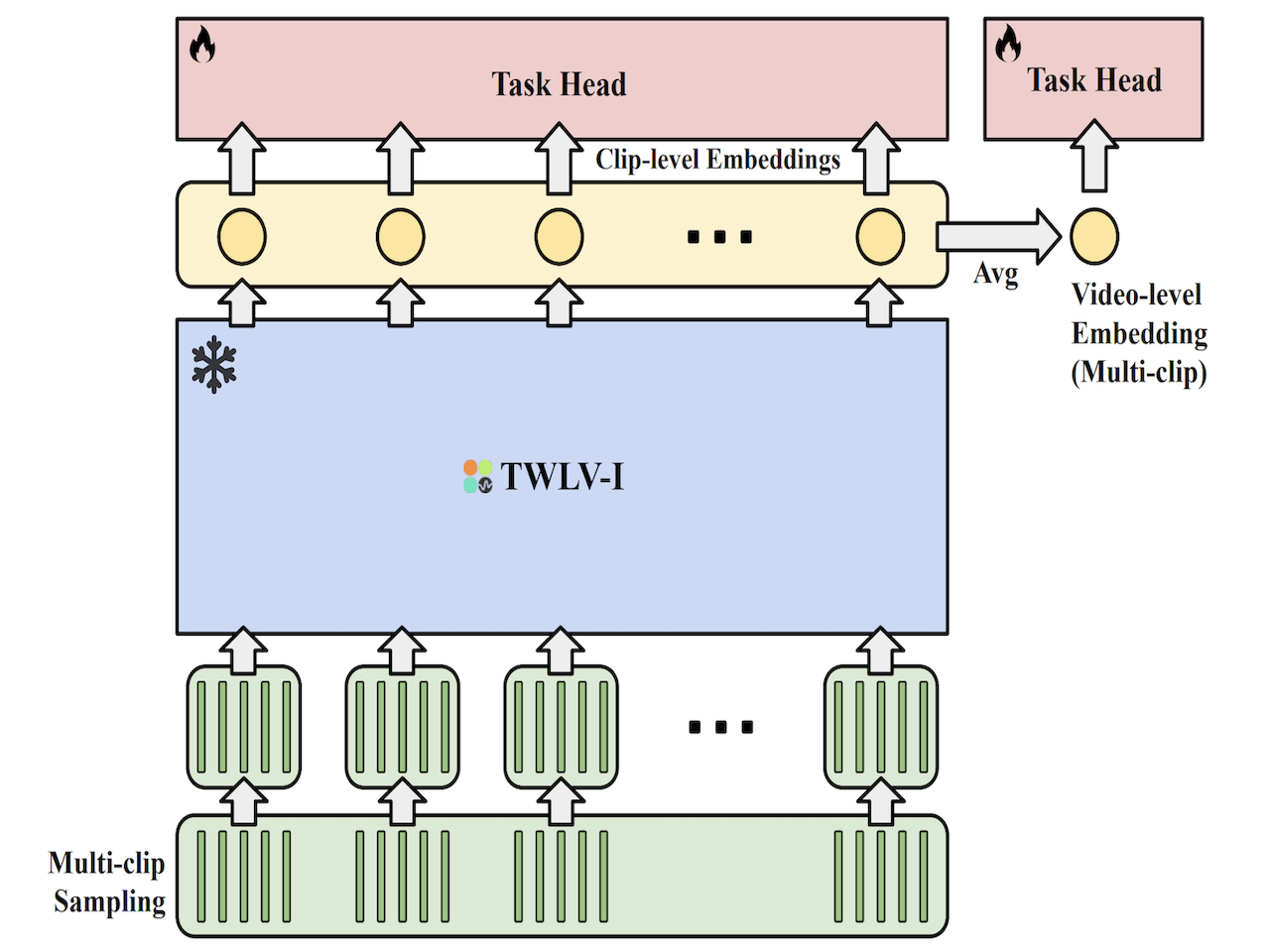
|
Twelve Labs Technical Report arXiv, 24.08 paper |
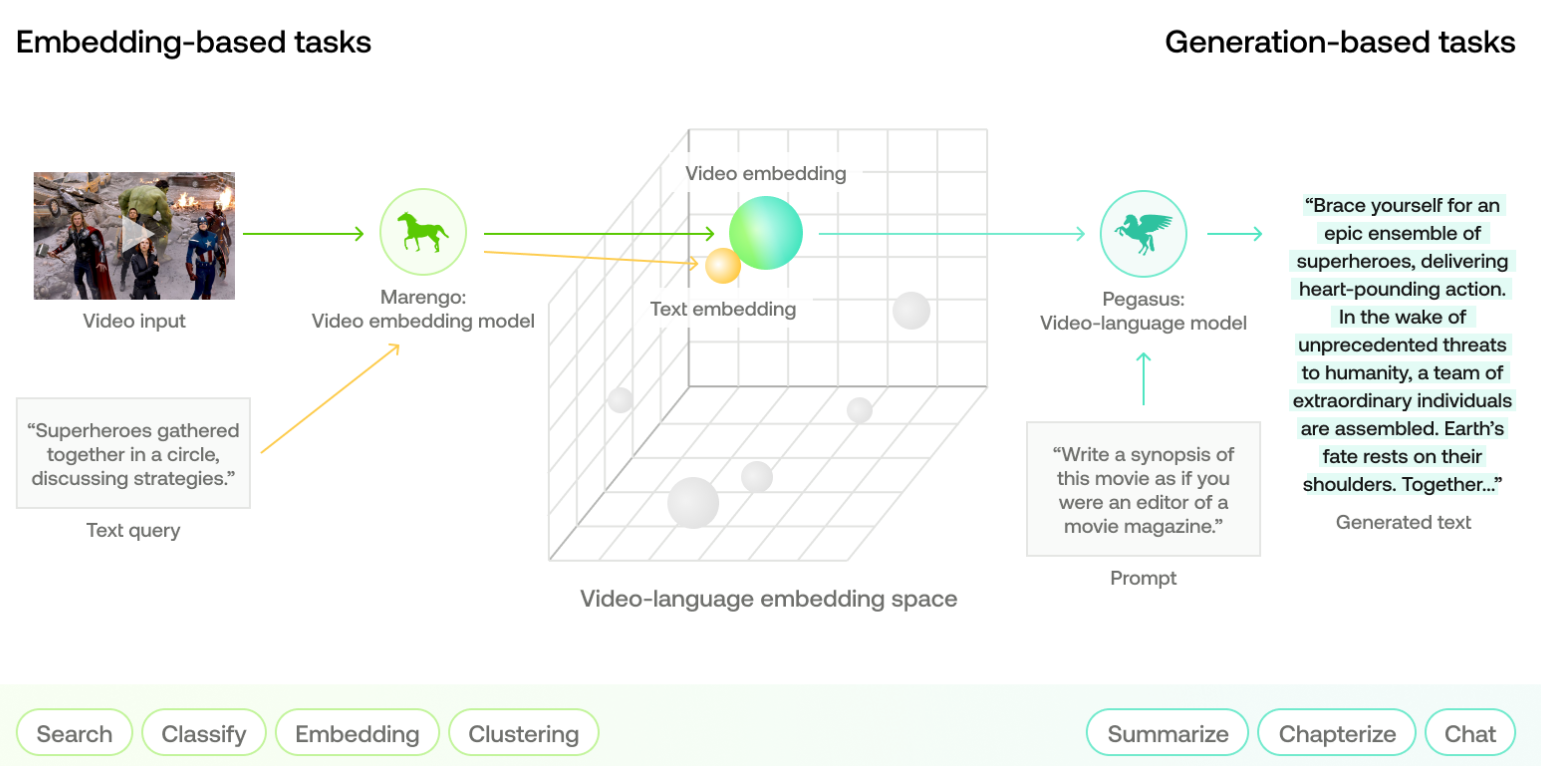
|
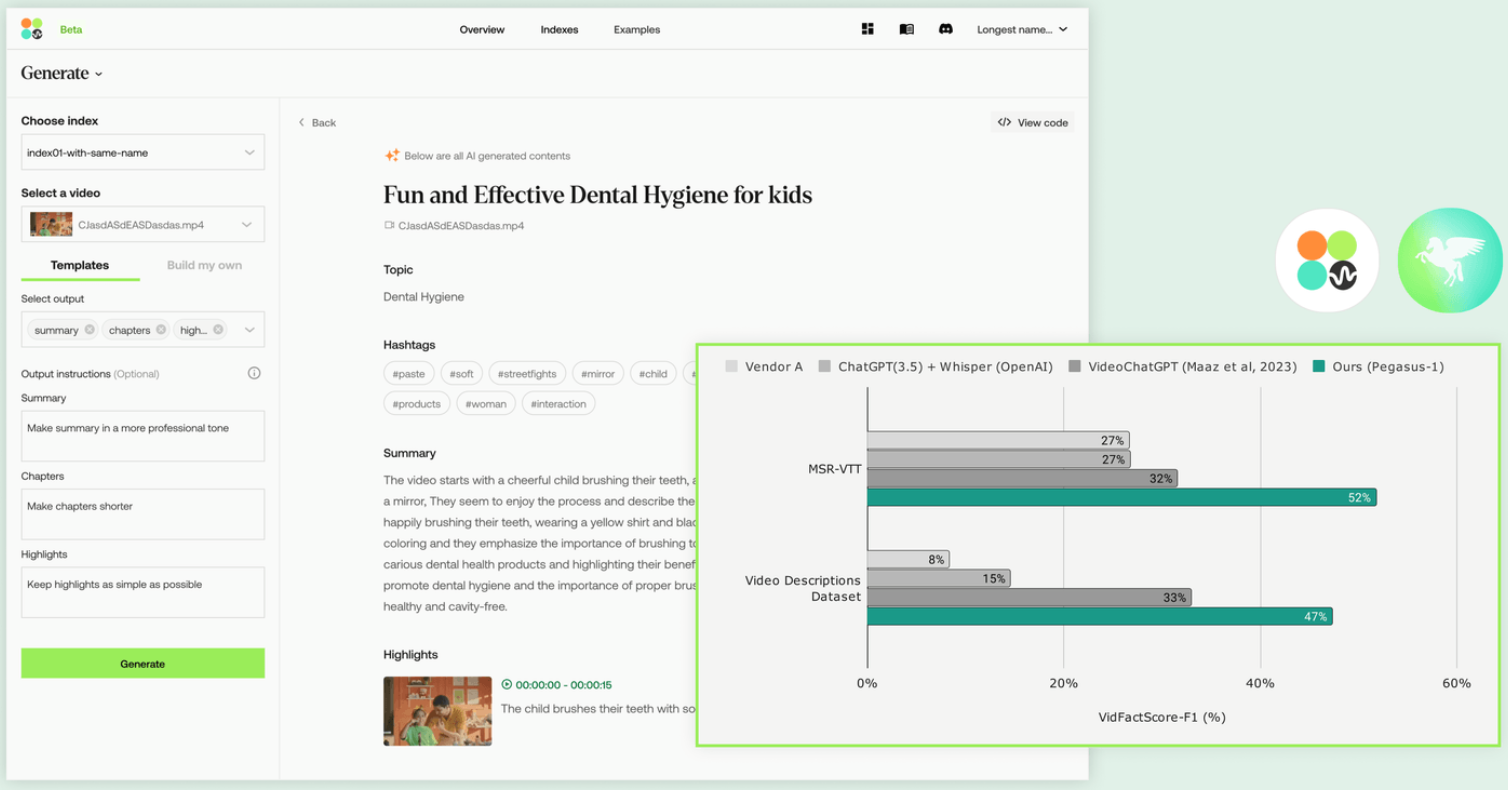
Twelve Labs Technical Report arXiv, 24.04 paper |
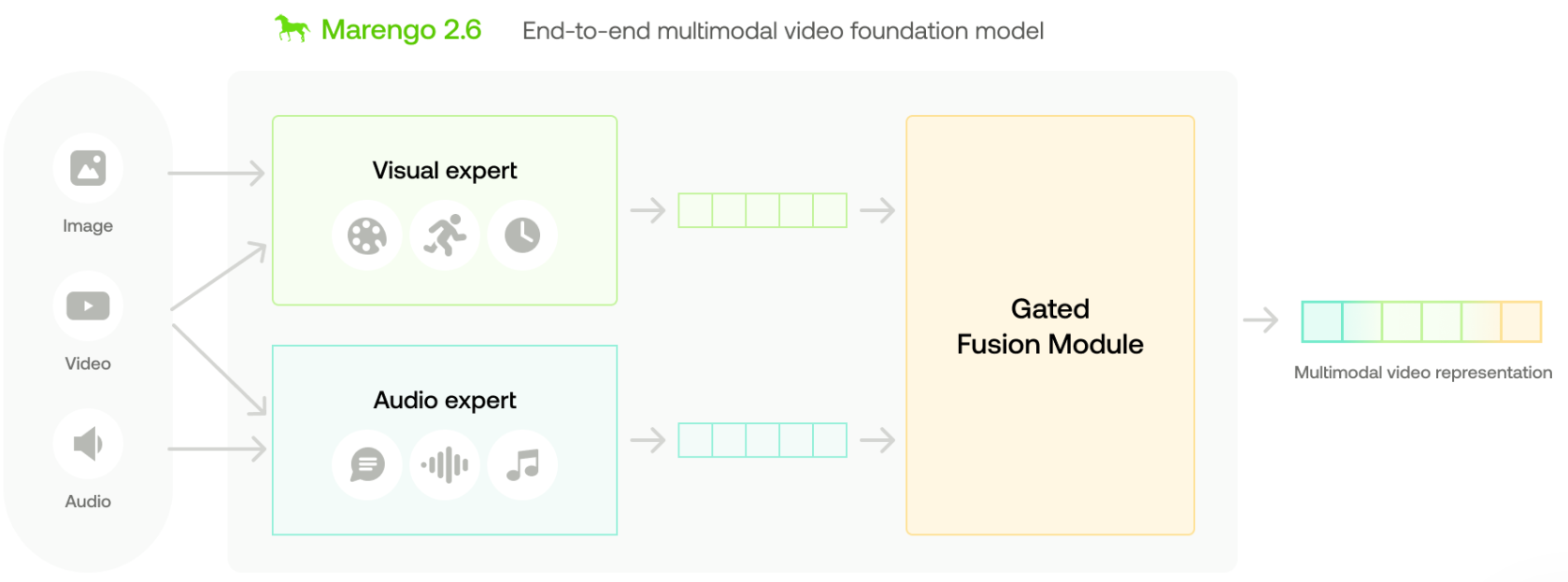
|
Twelve Labs Technical Blog, 24.03 blog |
|
|

|
Aug.2025 ~ Present |

|
Jan.2025 ~ May.2025 |
|
|
Sep.2023 ~ Jan.2025 June.2023 ~ Sep.2023 |
|
|
Mar.2021 ~ Jun. 2023 |

|
Jan.2022 ~ Mar.2022 |
|
|
Jun.2018 ~ Sep.2018 |
|
Source code credit to Dr. Jon Barron |